
Time to move on to Chomsky level 2! Level two languages are also known as context free languages, or CFLs. Level 2 languages are wonderful things. They’re simple enough to be parsed easily, but expressive enough to support a very wide range of useful languages. Pretty much every programming language that’s widely used can have its syntax specified with a level-2 language.
Grammars for Context Free Languages
In terms of the grammar, a CFL is easy to describe: it’s a language where the left-hand side of every grammar rule consists of exactly one non-terminal symbol. That’s it: the right hand side of a rule in a CFL grammar can be anything at all. Unlike the regular grammars, there are no restrictions on the position or the number of NTSs on the right hand side.
This change makes a huge difference in what you can do. In a CFL, you can count. You can have distant relationships – things like a sub-string that can occurs at the end of a string only if a match for it occurs at the beginning. The canonical example of this is paren matching: you can write a language that makes sure that you have matching parens: the same number of open and close parens.
-
A ::= '(' ')' -
A ::= A A
This language includes ()((())()()(())), but not ()((())()()(()) (the same thing, but with one trailing paren omitted – 8 opens, 7 closes), or ()((())()()(()))) (the same thing, but with an extra close paren at the end – 8 opens, 9 closes).
As a quick aside: this also illustrates what we mean when we say that a language supports counting. When we say that a language requires counting, what we mean is that is that some feature of a string in the language has to have a number of repetitions dictated by another feature in the same string. In a paren-matching grammar, we require that the number of close parens must be the same as the number of open parens. We don’t just make sure that that’s true for 1, or 2, or 3 open parens, we have matching close parens. For any number of parens, the number of closes must be the same as the number of opens.
We can look at a much less trivial example of a simple grammar. As I’ve written about at other times, in computer science, there’s a formal language that we use for a ton of valuable things called lambda calculus. Lambda calculus is the formal mathematical basis of the Haskell language, and the basic tool used for specifying formal semantics of computational systems. The complete grammar of the simply typed lambda calculus is:
-
ident ::= "A" | "B" | "C" | ... | "Z" -
expr ::= "" ident "." expr
-
expr ::= ident -
expr ::= expr expr -
expr ::= "(" expr ")"
You can see a practical example of counting in this grammar. It guarantees that expressions in the lambda calculus are well-formed. We couldn’t do that in a regular language. That’s a huge boost in capability.
So why do we call this a context free language? In terms of the grammar, when we’re constructing a string, we’re always doing it by replacing non-terminal symbols with sequences of other symbols. When we do one of those replacements, if there’s an NTS “S” in the current string, then we can replace it. We can’t look at anything but the individual non-terminals in the string. We can’t consider the context in which a non-terminal occurs before we decide whether or not we’re allowed to replace it.
Capability of Context Free Languages
As we’ve seen, CFLs give us some pretty significant additional capabilities. That abilities to count and to describe non-consecutive relationships between different parts of a string in a language are a huge upgrade in computational capability. But CFLs are still pretty limited in many ways. You can’t write a grammar for a spoken language using CFGs – natural languages aren’t context free. We use CFLs and CFGs all the time for compilers and such in real programs, but there’s always an extra step involved, because there are aspects of real computer languages that can’t be captured in context-free form.
So what can’t you do in a CFL? I’m not going to try to formally characterize the limits of CFLs, but here are two examples:
- Complex counting/Arithmetic
- if you want a language of strings with the same number of Xs and Ys, that language is a CFL. If you want a string with the same number of Xs, Ys, and Zs – that isn’t.
- Constrained relationships
- We can have some distant relationships in a context grammar – but it’s a very limited capability. You can’t specify that a particular symbol can only occur in one place in the string if it already occured in a prior part of the string. For example, in the lamba calculus example, it really should say that you can only use the “expr ::= ident” rule if the ident occured in an enclosing LAMBA ident”. CFLs can’t do that.
Computing CFLs: the PushDown Automaton
So – now that we know what a CFL is, and what it can express: what’s
the basic computational model that underlies them? CFLs are computable using a kind of machine called a pushdown automaton (PDA). Pushdown automata are relatively simple: take a finite state machine, and add a stack.
For the non-CS folks out there, a stack is a last in first out (LIFO) storage system. What that means is that you can store something on the top of the stack whenever you want to (called pushing), look at what’s on top of the stack (peeking), and removing the element on top (popping). For a PDA, the transitions look like:
 rightarrow (mbox{state}, mbox{stack-action})")
- The top-of-stack in the transition can be either a symbol from the machine’s alphabet, or it can be “*”. If it’s a symbol, then the transition can only be taken if both the machine state and the top-of-stack match. If it’s “*”, then the transition can be taken regardless of the value on top of the stack.
- The stack-action can be “push(symbol)”; “pop”, or “none”.
- The machine accepts the input if it reaches a final state with the stack empty. (There are alternate formulations that don’t require an empty stack, or that only require an empty stack but don’t use final states. They’re exactly equivalent to empty stack + final state.)
As usual, it’s easiest to understand this with an example. So let’s look at a simple language consisting of parens and identifiers, where the parens have to match. So, for example, “((I)(((I)I)(II)))” would be accepted, but “(I)(((I)I)(II)))” (the same string, but with the first open removed) would be rejected.
Our machine has an alphabet of “(“, “)”, and “I”. It has two states: 0, and 1. 0 is both the initial state, and the only final state. The available transitions are:
-
: in state 0, if you see an open paren, push it onto the stack, and stay in state 0 It doesn’t matter what’s on the stack – if there’s an open-paren in state 0, you can do this.
-
: in state 0, if you see a close paren and there’s an open-paren on top of the stack, then you’ve matched a pair, so you can pop the top open off of the stack.
-
: if you’re in state 0, and you see a close paren, but the stack in empty, then go to state one. State one is an error state: it means that you saw a close paren without a corresponding open paren. That’s not allowed in this grammar. Once you’re in state 1, you’re stuck.
-
: in state zero, if you see an “I”, then you consume it and continue in state zero. It doesn’t matter what’s on the stack, and you don’t change the stack.
Or graphically:

So – if it sees a “(“, it pushes a “(” on the stack. If it sees an identifier, it just keeps going past it. If it sees a “)”, and there’s an “(” on top of the stack, it pops the stack; if it sees a “)” and there’s no “(” on the stack, then it switches into state 1. Since state 1 is not a final state, and there is no transitions that can be taken from state 1, the machine rejects the string if it sees an extra “)”. If there’s a “(” without a matching close, then when the machine finishes, it will have a non-empty stack, and so it will reject the string.
Finally, one nifty little note. The pushdown automaton is a very limited kind of machine. It can’t do complex arithmetic, or process complex grammatical constructions. There’s a lot that it can’t do. So what happens if we take this very limited machine, and give it a second stack?
It becomes maximally powerful – Turing complete. In fact, it becomes a Turing machine. We’ll see more about Turing machines later, but a Turing machine is equivalent to a two-stack PDA, and a Turing
machine can perform any computation computable by any mechanized computing process. So one stack is extremely constrained; two stacks is as un-constrained as any computing device can ever be.
 , you can derive a new regular expression called the derivative with respect to symbol
, you can derive a new regular expression called the derivative with respect to symbol  ,
, ") .
. ") is the interpretation of the predicate
is the interpretation of the predicate  , then the complement of
, then the complement of ") .
.  requires three sets for a predicate: the extension, the counterextension, and the fringe. The fringe of a predicate
requires three sets for a predicate: the extension, the counterextension, and the fringe. The fringe of a predicate  is the set of values
is the set of values  for which
for which ") is
is  .
. for first order
for first order  , called the domain of the logic. This is the set of objects that the logic can be used to reason about.
, called the domain of the logic. This is the set of objects that the logic can be used to reason about. (that is, taking
(that is, taking ") ,
, ") , and
, and ") , such that:
, such that:
 .
.  cup cext(P) cup fringe(P) = D^n") .
. in the logic, an assignment of
in the logic, an assignment of  in D")
, I(y), I(z)) in ext(P)") ; it’s dissatisfied if
; it’s dissatisfied if , I(y), I(z)) in cext(P)") . Otherwise,
. Otherwise, , I(y), I(z))") must be in
must be in  of
of  is a variable assignment where for every variable
is a variable assignment where for every variable  except
except  . In other words, it’s an assignment where all of the variables except x have the same value as in
. In other words, it’s an assignment where all of the variables except x have the same value as in  ,
,  is satisfied by
is satisfied by  is
is  (true) if it is satisfied by every variable assignment on
(true) if it is satisfied by every variable assignment on  (false) if it’s dissatisfied by every variable assignment on
(false) if it’s dissatisfied by every variable assignment on  , Kleene’s strong 3-valued logic. In
, Kleene’s strong 3-valued logic. In  ” isn’t a number: it’s a notation that we understand refers to the number that you get by dividing one by two.
” isn’t a number: it’s a notation that we understand refers to the number that you get by dividing one by two. , the decimal notation is fundamental. The set of new real numbers consists exactly of the set of numbers with finite representations in decimal form. This leads to some astonishingly bizarre things. From his paper:
, the decimal notation is fundamental. The set of new real numbers consists exactly of the set of numbers with finite representations in decimal form. This leads to some astonishingly bizarre things. From his paper: ? Ill-defined, it doesn’t really exist. All of those triangles, circles, everything that depends on e? They’re all bullshit according to Escultura. Because if he can’t write them down in a piece of paper in decimal notation in a finite amount of time, they don’t exist.
? Ill-defined, it doesn’t really exist. All of those triangles, circles, everything that depends on e? They’re all bullshit according to Escultura. Because if he can’t write them down in a piece of paper in decimal notation in a finite amount of time, they don’t exist. , is (1-0.99999999…) and
, is (1-0.99999999…) and 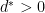 is the smallest number greater than 0. And you can generate a complete ordered enumeration of all of the new real numbers,
is the smallest number greater than 0. And you can generate a complete ordered enumeration of all of the new real numbers,  .
. . Escultura says he’s disproven this:
. Escultura says he’s disproven this:10") is not an integer. Surely he’s not that stupid. Surely he can’t possibly believe that he’s disproven Fermat using non-integer solutions? I mean, how is this different from just claiming that you can use (2, 3, 351/3) as a counterexample for n=3?
is not an integer. Surely he’s not that stupid. Surely he can’t possibly believe that he’s disproven Fermat using non-integer solutions? I mean, how is this different from just claiming that you can use (2, 3, 351/3) as a counterexample for n=3? . That’s the multiplicative inverse of 9. So, by definition,
. That’s the multiplicative inverse of 9. So, by definition,  – the multiplicative identity.
– the multiplicative identity. ") . So
. So ") is also a multiplicative identity. By a similar process, you can show that
is also a multiplicative identity. By a similar process, you can show that  , or else you’ve lost the field structure, and with it, pretty much all of real number theory.
, or else you’ve lost the field structure, and with it, pretty much all of real number theory.