
Today I’m going to show you the basic idea behind the equivalency of closed cartesian categories and typed lambda calculus. I’ll do that by showing you how the λ-theory of any simply typed lambda calculus can be mapped onto a CCC.
First, let’s define the term “lambda theory”. In the simply typed lambda calculus, we always have a set of base types – the types of simple atomic values that can appear in lambda expressions. A lambda theory is a simply typed lambda calculus, plus a set of additional rules that define equivalences over the base types.
So, for example, if one of the base types of a lambda calculus was the natural numbers, the lambda theory would need to include rules to define equality over the natural numbers:
- x = y if x=0 and y=0; and
- x = y if x=s(x’) and y=s(y’) and x’ = y’
So. Suppose we have a lambda-theory 
")



The semantics of the lambda-theory can be defined by a functor; in particular, a cartesian closed functor 
We describe how we build the category for the lambda theory in terms of a CCC using something called an interpretation function. It’s really just a notation that allows us to describe the translation recursively. The interpretation function is written using brackets: ![[A]](http://l.wordpress.com/latex.php?latex=%5BA%5D&bg=FFFFFF&fg=000000&s=0 "[A]")
So, first, we define an object for each type in
type, which we call unit. The idea behind unit is that we need to be able to talk about “functions” that either don’t take any real paramaters, or functions that don’t return anything. Unit is a type which contains exactly one atomic value. Since there’s only one possible value for unit, and unit doesn’t have any extractable sub-values, conceptually, it doesn’t ever need to be passed around. So it’s a “value” that never needs to get passed – perfect for a content-free placeholder.
Anyway, here we go with the base rules:
![\forall A \in \mbox{basetypes}(L), [A] = A_C \in C(L)](http://l.wordpress.com/latex.php?latex=%5Cforall%20A%20%5Cin%20%5Cmbox%7Bbasetypes%7D%28L%29%2C%20%5BA%5D%20%3D%20A_C%20%5Cin%20C%28L%29&bg=FFFFFF&fg=000000&s=0 "\forall A \in \mbox{basetypes}(L), [A] = A_C \in C(L)")
![[\mbox{unit}] = 1_C](http://l.wordpress.com/latex.php?latex=%5B%5Cmbox%7Bunit%7D%5D%20%3D%201_C&bg=FFFFFF&fg=000000&s=0 "[\mbox{unit}] = 1_C")
Next, we need to define the typing rules for complex types:
![[ A \times B] == [A] \times [B]](http://l.wordpress.com/latex.php?latex=%5B%20A%20%5Ctimes%20B%5D%20%3D%3D%20%5BA%5D%20%5Ctimes%20%5BB%5D&bg=FFFFFF&fg=000000&s=0 "[ A \times B] == [A] \times [B]")
![[A \rightarrow B] = [B]^{[A]}](http://l.wordpress.com/latex.php?latex=%5BA%20%5Crightarrow%20B%5D%20%3D%20%5BB%5D%5E%7B%5BA%5D%7D&bg=FFFFFF&fg=000000&s=0 "[A \rightarrow B] = [B]^{[A]}")
Now for the really interesting part. We need to look at type derivations – that is, the type inference rules of the lambda calculus – to show how to do the correspondences between more complicated expressions. Just like we did in lambda calculus, the type derivations are done with a context 
![[ \emptyset ] = 1_C](http://l.wordpress.com/latex.php?latex=%5B%20%5Cemptyset%20%5D%20%3D%201_C&bg=FFFFFF&fg=000000&s=0 "[ \emptyset ] = 1_C")
![[\Gamma, x: A] = [\Gamma] \times [A]](http://l.wordpress.com/latex.php?latex=%5B%5CGamma%2C%20x%3A%20A%5D%20%3D%20%5B%5CGamma%5D%20%5Ctimes%20%5BA%5D&bg=FFFFFF&fg=000000&s=0 "[\Gamma, x: A] = [\Gamma] \times [A]")
We also need to describe what to do with the values of the primitive types:
- For each value
, there is an arrow
.
And now the rest of the rules. Each of these is of the form ![[\Gamma :- x : A] = \mbox{arrow}](http://l.wordpress.com/latex.php?latex=%5B%5CGamma%20%3A-%20x%20%3A%20A%5D%20%3D%20%5Cmbox%7Barrow%7D&bg=FFFFFF&fg=000000&s=0 "[\Gamma :- x : A] = \mbox{arrow}")


- Unit evaluation:
. (A unit expression is a special arrow “!” to the unit object.)
- Simple Typed Expressions:
. (A simple value expression is an arrow composing with ! to form an arrow from Γ to the type object of Cs type.)
- Free Variables:
(A term which is a free variable of type A is an arrow from the product of Γ and the type object A to A; That is, an unknown value of type A is some arrow whose start point will be inferred by the continued interpretation of gamma, and which ends at A. So this is going to be an arrow from either unit or a parameter type to A – which is a statement that this expression evaluates to a value of type A.)
- Inferred typed expressions:
, where
(If the type rules of Γ plus the judgement
, then the term
. This is almost the same as the previous rule: it says that this will evaluate to an arrow for an expression that results in type
- Function Abstraction:
. (A function maps to an arrow from the type context to an exponential
, which is a function from
- Function application:
,
,
. (function evaluation takes the eval arrow from the categorical exponent, and uses it to evaluate out the function.)
There are also two projection rules for the decomposing categorical products, but they’re basically more of the same, and this is already dense enough.
The intuition behind this is:
- arrows between types are families of values. A particular value is a particular arrow from unit to a type object.
- the categorical exponent in a CC is exactly the same thing as a function type in λ-calculus; and an arrow to an exponent is the same thing as a function value. Evaluating the function is using the categorical exponent’s eval arrow to “decompose” the exponent, and produce an arrow to the function’s result type; that arrow is the value that the function evaluates to.
- And the semantics – called functorial semantics – maps from the objects in this category,
Aside from the fact that this is actually a very clean way of defining the semantics of a not-so-simply typed lambda calculus, it’s also very useful in practice. There is a way of executing lambda calculus expressions as programs that is based on this, called the Categorical Abstract Machine. The best performing lambda-calculus based programming language (and my personal all-time-favorite programming language), Objective-CAML had its first implementation based on the CAM. (CAML stands for categorical abstract machine language.).
From this, you can see how the CCCs and λ-calculus are related. It turns out that that relation is not just cool, but downright useful. Concepts from category theory – like monads, pullbacks, and functors are really useful things in programming languages! In some later posts, I’ll talk a bit about that. My current favorite programming language, Scala, is one of the languages where there’s a very active stream of work in applying categorical ideas to real-world programming problems.

 has type
has type  , which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type
, which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type  , we can infer that the result type of this function will be
, we can infer that the result type of this function will be  .
.: \nu \rightarrow \nu")
 because the function type is
because the function type is  , which means that the function parameter has type
, which means that the function parameter has type 
 , I’ll write that as
, I’ll write that as  .
.

 , then inferring a type judgement about any other term cannot change our type judgement for
, then inferring a type judgement about any other term cannot change our type judgement for :\alpha \rightarrow \beta}")
 ; and if, with our knowledge of the parameter type, we know that the type of term that makes up the body of the function is
; and if, with our knowledge of the parameter type, we know that the type of term that makes up the body of the function is  , then we know that the type of the function is
, then we know that the type of the function is  .
.: \beta}")

 constructor. Other typed lambda calculi include the ability to define parametric types, which are types expressed as functions ranging over types.
constructor. Other typed lambda calculi include the ability to define parametric types, which are types expressed as functions ranging over types. , then given a inhabited type
, then given a inhabited type ") is true, I’ll say that x is a member of type P. In a quantifier, I’ll say things like
is true, I’ll say that x is a member of type P. In a quantifier, I’ll say things like  to mean
to mean  Rightarrow mbox{em foo}") . Used this way, we can say that P is a type predicate.
. Used this way, we can say that P is a type predicate.") , which is true if and only if x is one of the atoms that represents a natural number.
, which is true if and only if x is one of the atoms that represents a natural number.") , where
, where ") .
. ") .
. Leftrightarrow mbox{em succ}(x,y)")
")
")
 land mbox{em succ}(a,x) land mbox{em succ}(y,b) Rightarrow Sum(x, y, z)")
 Leftrightarrow sum(z,y,x)")
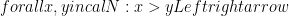
 . But we’ve violated that – we have both
. But we’ve violated that – we have both  , and
, and
 (note not cartesian closed category) is a category:
(note not cartesian closed category) is a category: , and
, and") , the objects and arrows of the categorical product
, the objects and arrows of the categorical product  .
. ,
, , called an evaluation map.
, called an evaluation map.") , an operation
, an operation  rightarrow (z rightarrow x^y)") . (That is, an operation mapping from arrows to arrows.)
. (That is, an operation mapping from arrows to arrows.) :
:
times 1_y)")
 = z")

 is the set of functions from Y to X.
is the set of functions from Y to X. is a function from
is a function from  to to
to to  to
to  .
.") ,
, ") maps
maps ") , and currying it to
, and currying it to (y)") .
.") selects a function from
selects a function from  to
to , y)") .
.
") is an initial object if and only if
is an initial object if and only if : \exists_1 f: o \rightarrow b \in Mor(C)") . We generally write
. We generally write  for the initial object in a category. Similarly, there’s a dual concept of a terminal object
for the initial object in a category. Similarly, there’s a dual concept of a terminal object  , which is object for which there’s exactly one arrow from every object in the category to
, which is object for which there’s exactly one arrow from every object in the category to  , where
, where ") such that
such that  and
and  . If an object is initial, then there’s an arrow from it to every other object — including the other initial object. And there’s an arrow back, because the other one is initial. The iso-arrows between the two initials obviously compose to identities.
. If an object is initial, then there’s an arrow from it to every other object — including the other initial object. And there’s an arrow back, because the other one is initial. The iso-arrows between the two initials obviously compose to identities.") , the categorical product
, the categorical product  consists of:
consists of: , often written
, often written  ;
; and
and  , where
, where ") ,
,  , and
, and  .
. , maps the pair of arrows
, maps the pair of arrows  and
and to an arrow
to an arrow  , where
, where  has the
has the



 and
and  , that
, that  is a mapping from
is a mapping from ") to an object
to an object  in Obj(D)") .
.") to an arrow
to an arrow  : F(x) rightarrow F(y)") , where:
, where:
: F(1_o) = 1_{F(o)}") . (Identity is preserved by the functor mapping of morphisms.)
. (Identity is preserved by the functor mapping of morphisms.): F(n circ o) = F(n) circ F(o)") . (Commutativity is preserved by the Functor mapping of morphisms.)
. (Commutativity is preserved by the Functor mapping of morphisms.)