
I’ve mentioned Gödel’s incompleteness theorems many times on this blog, but I’ve never actually written about them in detail. I was asking, on twitter, for topics that readers would be interested in, and one thing that came up is actually go through the proof of incompleteness. I’m happy to take the time to do that incompleteness is one of the most beautiful and profound proofs that I’ve ever seen.
It takes a fair bit of effort though, so it’s going to take a couple of posts just to get through the preliminaries. What I’m going to do is work with this translation of the original paper where Gödel published his first incompleteness proof. Before we can get to the actual proof, we need to learn a bit about the particular kind of logic that he used in his proof.
The story of incompleteness is really pretty interesting. In the late 19th and early 20th centuries, mathematicians started to get really interested in formal foundations. Why, exactly, this happened is somewhat of a debate, but the story I find most likely is that it’s a result of Cantor and his naive set theory.
Set theory came along, and it seemed like such a great idea. It seems incredibly simple, and it makes many proofs in many different subject areas appear to be really simple. But there’s a huge problem: it’s not consistent.
The problem is what’s come to be known as Russell’s paradox. I’ve explained Russell’s paradox a bunch of times on the blog. For this post, I’m going to do it a bit differently. As part of my prep for this series of posts, I’ve been reading the book Gödel’s Proof, and in that book, they have a way of rephrasing Russell’s paradox which I think clarifies it nicely, so I’m going to try their version.
If you think about the set of all sets, you can partition it into two non-overlapping subsets. There’s a subset of normal sets, and a class of abnormal sets. What makes a set abnormal is that it’s self-referential – an abnormal set contains itself as a member.
So considered the set of all normal sets. Is it, itself, a normal set?
The answer is: argh! Because if the set of all normal sets is normal, then it must be a member of itself. But if it’s a member of itself, it can’t be normal. Similarly, if you start off saying that the set of all normal sets isn’t normal, then by definition, it is normal. No matter what you do, you’re screwed.
What Russell’s paradox did was show that there was a foundational problem in math. You could develop what appeared to be a valid mathematicial structure and theory, only to later discover that all the work you did was garbage, because there was some non-obvious fundamental inconsistency in how you defined it. But the way that foundations were treated simple wasn’t strong or formal enough to be able to detect, right up front, whether you’d hard-wired an inconsistency into your theory. So foundations had to change, to prevent another Cantor incident.
So, eventually, along came two mathematicians, Russell and Whitehead, and they created an amazing piece of work called the Principia Mathematica. The principia was supposed to be an ideal, perfect mathematical foundation. The Principia was supposed to have two key properties: it was supposed to consistent, and it was supposed to be complete.
- Consistent meant that the statement would not allow any inconsistencies of any kind. If you used the logic and the foundantions of the Principia, you couldn’t even say anything like Russell’s paradox: you couldn’t even write it as a valid statement.
- Complete meant that every true statement was provably true, every false statement was provably false, and every statement was either true or false.
A big part of how it did this was by creating a very strict stratification of logic. You could reason about a specific number, using level-0 statements. You could reason about sets of numbers using level-1 statements. And you could reason about sets of sets of numbers using level-2 statements. In a level-1 statement, you could make meta-statements about level-0 properties, but you couldn’t reason about level-1. In level-2, you could reason about level-1 and level-0, but not about level-2. This meant that you couldn’t make a set like the set of normal sets – because that set is formed using a predicate – and when you’re forming a set like “the set of proper sets”, the sets you can reason about are a level below you. You can form a level-1 set using a level-1 statement about level-0 objects. But you can’t make a level-1 statement about level-1 objects! So self-referential systems would be completely impossible in the Principia’s logic.
As a modern student of math, it’s hard to understand what a profound thing they were trying to do. We’ve grown up learning math long after incompleteness became a well-known fact of life. (I read “Gödel Escher Bach” when I was a college freshman – well before I took any particularly deep math classes – so I knew about incompleteness before I knew enough to really understand what completeness woud have meant!) The principia would have been the perfection of math, a final ultimate perfect system. There would have been nothing that we couldn’t prove, nothing in math that we couldn’t know!
What Gödel did was show that using the Principia’s own system, and it’s own syntax, that not only was the principia itself flawed, but that any possible effort like the principia would inevitably be flawed!
With the incompleteness proof, Gödel showed that even in the Principia, even with all of the effort that it made to strictly separate the levels of reasoning, that he could form self-referential statements, and that those self-referential statements were both true and unprovable.
The way that he did it was simply brilliant. The proof was a sequence of steps.
- He showed that using Peano arithmetic – that is, the basic definition of natural numbers and natural number arithmetic – that you could take any principia-logic statement, and uniquely encode it as a number – so that every logical statement was a number, and ever number was a specific logical statement.
- Then using that basic mechanic, he showed how you could take any property defined by a predicate in the principia’s logic, and encode it as a arithmetic property of the numbers. So a number encoded a statement, and the property of a number could be encoded arithmetically. A number, then, could be both a statement, and a definition of an arithmetic property of a stament, and a logical description of a logical property of a statement – all at once!
- Using that encoding, then – which can be formed for any logic that can express Peano arithmetic – he showed that you could form a self-referential statement: a number that was a statement about numbers including the number that was statement itself. And more, it could encode a meta-property of the statement in a way that was both true, and also unprovable: he showed how to create a logical property “There is no proof of this statement”, which applied to its own numeric encoding. So the statement said, about itself, that it couldn’t be proven.
The existence of that statement meant that the Principia – and any similar system! – was incomplete. Completeness means that every true statement is provably true within the system. But the statement encodes the fact that it cannot be proven. If you could prove it, the system would be inconsistent. If you can’t, it’s consistent, but incomplete.
We’re going to go through all of that in detail. But to do that in a way where we can really understand it, we’re going to need to start by looking at the logic used by the Principia. Then we’ll look at how to encode Principia-logical statements as natural numbers using a technique called Gödel numbering, and how to express predicates numerically. And then, finally, we can look at how you can form the classic Gödel statement that shows that the Principia’s system of logic is incomplete.

 has type
has type  , which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type
, which we’ll use as the type name for the natural numbers. (In case it’s hard to tell, that’s a greek letter “nu” for natural.) There is no assertion of the type of the result of the function; but since we know that “+” is a function with type  , we can infer that the result type of this function will be
, we can infer that the result type of this function will be  .
.: \nu \rightarrow \nu")
 because the function type is
because the function type is  , which means that the function parameter has type
, which means that the function parameter has type 
 , I’ll write that as
, I’ll write that as  .
.

 , then inferring a type judgement about any other term cannot change our type judgement for
, then inferring a type judgement about any other term cannot change our type judgement for :\alpha \rightarrow \beta}")
 ; and if, with our knowledge of the parameter type, we know that the type of term that makes up the body of the function is
; and if, with our knowledge of the parameter type, we know that the type of term that makes up the body of the function is  , then we know that the type of the function is
, then we know that the type of the function is  .
.: \beta}")

 constructor. Other typed lambda calculi include the ability to define parametric types, which are types expressed as functions ranging over types.
constructor. Other typed lambda calculi include the ability to define parametric types, which are types expressed as functions ranging over types. , then given a inhabited type
, then given a inhabited type ") is true, I’ll say that x is a member of type P. In a quantifier, I’ll say things like
is true, I’ll say that x is a member of type P. In a quantifier, I’ll say things like  to mean
to mean  Rightarrow mbox{em foo}") . Used this way, we can say that P is a type predicate.
. Used this way, we can say that P is a type predicate.") , which is true if and only if x is one of the atoms that represents a natural number.
, which is true if and only if x is one of the atoms that represents a natural number.") , where
, where ") .
. ") .
. Leftrightarrow mbox{em succ}(x,y)")
")
")
 land mbox{em succ}(a,x) land mbox{em succ}(y,b) Rightarrow Sum(x, y, z)")
 Leftrightarrow sum(z,y,x)")
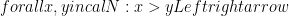
 . But we’ve violated that – we have both
. But we’ve violated that – we have both  , and
, and
") is the interpretation of the predicate
is the interpretation of the predicate  , then the complement of
, then the complement of ") .
.  requires three sets for a predicate: the extension, the counterextension, and the fringe. The fringe of a predicate
requires three sets for a predicate: the extension, the counterextension, and the fringe. The fringe of a predicate  is the set of values
is the set of values  .
. for first order
for first order  , called the domain of the logic. This is the set of objects that the logic can be used to reason about.
, called the domain of the logic. This is the set of objects that the logic can be used to reason about. (that is, taking
(that is, taking ") ,
, ") , and
, and ") , such that:
, such that:
 .
.  cup cext(P) cup fringe(P) = D^n") .
. in the logic, an assignment of
in the logic, an assignment of  in D")
, I(y), I(z)) in ext(P)") ; it’s dissatisfied if
; it’s dissatisfied if , I(y), I(z)) in cext(P)") . Otherwise,
. Otherwise, , I(y), I(z))") must be in
must be in  of
of  is a variable assignment where for every variable
is a variable assignment where for every variable  except
except  . In other words, it’s an assignment where all of the variables except x have the same value as in
. In other words, it’s an assignment where all of the variables except x have the same value as in  ,
,  is satisfied by
is satisfied by  is
is  (true) if it is satisfied by every variable assignment on
(true) if it is satisfied by every variable assignment on  (false) if it’s dissatisfied by every variable assignment on
(false) if it’s dissatisfied by every variable assignment on  , Kleene’s strong 3-valued logic. In
, Kleene’s strong 3-valued logic. In