
I’ve been writing this blog for a long time. It’s pretty amazing to me to realize just how long – the original version of Good Math/Bad Math started over 9 years ago! I’ve gone through some times when the blog was really busy, and some when it was really slow. Lately, it’s been the latter. Since my mom died a few months back, I’ve been depressed, and finding enough motivation to blog after a full day of work has been difficult. But I’m trying to get back to normal, and start updating the blog at least a couple of times a week.
A few weeks back, one of my blog-friends asked me to write about type theory. Type theory comes up a lot in programming language design, particularly in the functional programming world. If you can’t talk intelligently about quantified types, existential types, dependent types, and similar stuff, you’re largely locked out of discussions.
I’ve taken a couple of weak stabs at type theory over the years, but I’ve never tried to really do it justice. It’s a hard topic, and even though it’s got a lot of overlap with my professional focus, I’ve never been formally trained in it. I’ve never actually taken a course in type theory – I’ve learned it on my own, as I’ve studied programming languages and denotational semantics.
Now seems like a good time to give it a try. It’s a subject that I’m obviously pretty interested in.
To start, I’m going to recycle a couple of old posts. I’ve written about the simplest version of type theory that I know, something called ST. I’m rewriting tha old post here. After that, I’ll rewrite some material about the simply typed lambda calculus, putting into a more type-theoretic framework. Then I’ll move from there into basic type theory, intuitionistic type theory, and the various type system heirarchies, like System-T, System-F, Lambda-cube, etc.
So, today: ST type theory.
I’ve said many times that I’m a programming language guy, and that’s how I approach this stuff. For someone who works on programming languages, types are old hat. They seem like such an obvious idea that it’s hard to conceive of a world in which they aren’t a part of the mathematical background. But in the world of math, they’re a relatively recent invention. (In computer science, they’re ancient history: type theory predates the first real computers.)
The roots of type theory are the same as the roots of axiomatic set theory. The point wasn’t to support anything computational; the point was to try to salvage set theory. Cantor had devised set theory, and once people started to understand it, the mathematical community thought it was the neatest thing ever! Set theory was just wonderful! Except for the part where it was a total inconsistent train wreck.
Mathematicians love set theory. It’s a system on which all of mathematics can be built, using a basis which is simple, using nothing but intuitively clear concepts. That’s lovely. Unfortunately, as we know, simple intuitive ideas often don’t work. Cantor’s set theory had a huge problem: it was inconsistent.
Here’s the problem.
In set theory, you’ve got these collection of things called sets. The main thing that you can do with sets is say, “I’ve got this object here. You’ve got a set. Is my object part of your set?”. For any possible pair of object and set, there can be only one correct answer: either the object is in the set, or it isn’t. There’s no middle ground: there’s no way an can be both in and not in a set.
In Cantor’s version of set theory, you could define a set using logic, in a process called comprehension. He said that if you can write a logical predicate, then there’s a set which contains the collection of objects that satisfy that predicate. Using comprehension, you can define sets that range over sets. For example, you can define the set of all sets with an even number of elements.
The catch is that Cantor didn’t place any restrictions on those predicates. So you can create sets based on predicates that range over themselves. You can define a set which is a member of itself, like the set of all sets.
Using that, you can make up some silly sets. For example: Is the set of all sets that contain themselves a member of itself?
Well, if it is, then it is. If it isn’t, then it isn’t. Both yes and no! The english statement, “the set of all sets that contain themselves”, doesn’t uniquely identify one set. There are two different sets that match that description! There’s one that does contain itself, and there’s one that doesn’t!
We’ve already a problem in a lesser way: even written in careful predicate logic, the definition is ambiguous when it shouldn’t be. But there’s more trouble ahead. If we can define the set of all sets that do contain themselves as a member, then we can also define the set of all sets that do not contain themselves as a member.
Let 

If 
That’s a demonstration of the fundamental inconsistency in Cantor’s set theory, and it’s commonly known as Russell’s paradox. It’s caused by the ability to build unlimited self-referential statements about sets and set membership.
Inconsistency is a big deal in mathematics: if you’re working in an inconsistent system, then every statement is provably true in that system. That’s another way of saying that proving something in an inconsistent system is completely useless, because the proof doesn’t actually tell you that the thing you proved is true!
Using Cantor’s formulation of set theory, I can start with a statement that I know really is true, and I can work out a valid proof to show that it’s true. But I can also start with a statement that I know is false, and I can work out a perfectly valid proof that shows that false statement is true. I can prove that the sum of the integers from 1 to N is (n+1)}{2}")

Any inconsistenty in a formal system means that the entire system is useless. Russell’s paradox meant that nothing that had been proven with set theory could be trusted! None of the methods of proof that people had come to love from working with set theory could be followed, because the entire basis was inconsistent!
Mathematicians wanted to find a way to preserve as much of set theory as possible, while getting rid of the inconsistency. That led to a lot of different systems. I’ve talked a lot on this blog about axiomatic set theory, which was the most well-known and widely accepted approach to the problem. Type theory is a different one.
What type theory does is start with a notion very similar to sets: collections of objects. The difference is that in type theory, instead of having sets which define collections of objects using logical predicates, in type theory, you have collections called types. The types are highly stratified, in a way that prevents you from creating anything self-referential.
The way that you do that is by building a ladder of types. Any type theory has some collection of primitive atoms. An atom is, as the name suggests, a simple object which isn’t made up of other objects. An atom is just itself – it doesn’t contain anything.
In our ladder of types, we start with the atoms. Atoms are level-0 objects. Using atoms, you can define types, which are collections of atoms. A level-1 type is defined by a predicate over level-0 objects. The level-1 type is, itself, a level-1 object. So a level-1 object is a collection of level-0 objects. A level-1 type can only range over level-0 objects, so it’s impossible for a level-1 object to contain itself. No self-reference paradox can even be written here!
You can continue the process by adding new levels. You can define level-1 predicates (that is, predicates ranging over level-1 types) – and the resulting collection is a level-2 type. And so on: any level-N type is a collection of types from level N-1, defined by a level N-1 predicate.
This produces a strict ladder of types and objects, and no type can contain anything from its own level. Russell’s paradox is averted. But the cost is complexity: most theorems that were provable in set theory are also provable in type theory, but they’re often a lot more complicated, both in how they’re stated, and in how they’re proven.
Of course, as I always say, informal explanations of formal things are always wrong. Formality exists for a reason: it allows us to say things in precise, unambiguous ways. If we want to understand even the simplest bits of type theory, we can’t just stop with the informal explanation: we need to hit the formalisms as well.
We’re going to start with the simplest version of type theory, a system called ST. ST is defined axiomatically. The axioms are, mostly, very similar to the basics of axiomatic set theory – especially to the NBG formulation. In NBG set theory, we have a collection of axioms that define what sets are and how they work. We define set equality with an axiom of extensionality; we define how we can construct new sets using logical predicate via an axiom of comprehension; we define the existence of infinite sets using an axiom of infinity. In ST type theory, we have similar axioms – identity/extensionality, comprehension, and infinity (but as we’ll see, the ST axiom of infinity is strange and back-handed compared to NBG).
The axioms explicitly capture the idea of stratification that I described informally above. In each axiom, I’ll refer to objects of one level using lowercase letters; I’ll write objects of the next higher level by appending a prime-mark to the letters. So if 
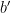
ST has four axiom schemas.
- Axiom of Identity:
This is straightforward – it’s an upside-down version of the axiom of extensionality in NBG set theory. If two objects are members of exactly the same collection of types, then they’re equal. Another way of saying that is that two objects are equal if there is no predicate that can distinguish between them.
-
Axiom of Extensionality:
This is pretty much an exact copy of the NBG axiom of extensionality, except that it specifies the fact that an object
can only be in a type
that is one level higher than
- Axiom of Comprehension: If
is a
th-order predicate, then
This is very similar to the axiom of comprehension from NBG set theory, modified for the strict stratification of type theory. It says that if there’s a predicate over level-
type.
- Axiom of Infinity:
There exists a relation, “”, which ranges over pairs of atoms, and which is total, irreflexive, transitive, and strongly connected, such that
.
This axiom is a strange beast. It’s defining the fact that there is an infinitely large type, but it’s doing it in a very backhanded way. In set theory, we were able to use Cantor numbers to define an infinite sequence of sets corresponding to natural numbers – and then using the construction of natural numbers with the other axioms, we could build more expansive sets of numbers – integers, reals, complex, etc.
But in type theory, we can’t do that. The Cantor numbers are defined by using things that belong not just to different types, but to different type strata. In cantor numbers, the number
In ST type theory, there’s no simple constructive way of building an infinite collection like the Cantor numerals which doesn’t violate the stratification of type theory. So type theory needs to go at in a different way.
The way it does it is by defining a relation between atoms that can only be satisfied by an infinitely large set. The existence of the relation over the type implies that the type must also exist. The relation itself isn’t that hard – what’s hard about it is grasping the full implication of it. The relation is just something that behaves like numeric less-than:
- It’s a relation over a pair of values. You can think of it as a function,
.
- It’s total, meaning that every possible value
appears as both the left and the right parameter of <: so no matter what, for any value
where
, and some atom
where
.
- It’s irreflexive: so there is no smallest number
.
- It’s transitive – so if
, then
.
- It’s strongly connected – so there isn’t a group of free-standing finite pools.
All of that, together, means that there’s an infinitely large pool of numbers, and that they’ve got enough properties to represent the integers.
- It’s a relation over a pair of values. You can think of it as a function,



ST type theory is, in my opinion, a mixed bag. From the perspective of a programming language guy, we haven’t gotten anything out of it that’s particularly valuable. It’s not particularly expressive. It is a simpler system, axiomatically, than type theory – and that’s nice. But proofs written using this kind of theory as a basis are more complicated – sometimes a lot more complicated – than they’d be in NBG or ZF set theory. The additional effort to understand the set theory axioms has a payoff in making everything easier.
But ST is just a starting point. In fact, most programming language type systems are derived from a very different school of type theory: Per Martin-Lof’s intuitionistic type theory. The basic ideas are similar, but intuitionistic type theory is much more useful in computer science.
My condolences on the loss of your mother.
Also, I’m loving this topic and can’t wait for more.
Thanks for this. Way too few explainers for this sort of thing yet, especially as compared with topology and categories.
Ugh, big comment just got eated; how do I use latex in comments on this platform? Trying to reconstruct, at least in fragments…
Technical question: in the Axiom of Infinity, do you mean that “<" is total "over its domain" in some technical sense? Surely you don't mean to say that the collection (level-1) of all atoms (level-0) is totally ordered, do you?
More philosophical: you say that “[set theory is] a system on which all of mathematics can be built”, and that’s not wrong, but it feels a little outdated in light of more recent (within the last century) developments in the philosophy of mathematics. I’d say that mathematics concerns itself with structures, defined by axioms (or axiom schemata), and set theory is useful in the sense that we’ve been able to use it as the basis for models of many common structures.
For example, Peano arithmetic is defined by the usual axioms for the natural numbers: there is zero; there is a successor function; they satisfy certain relations. The ZF-standard construction of the finite von Neumann ordinals satisfies these axioms. There is zero (“{}”), and a successor (“n -> n U {n}”), and they satisfy the required relations, and so they furnish a model of PA within ZF.
More exactly, this construction shows us that if we have a model for ZF, we can use it to build a model for PA. There are other models for PA, even within ZF, and any one of them is just as good as any other. When we work within PA we ignore “implementation details”.
So, in order to not be totally didactic and self-congratulatory here, a question: is there a standard construction like this — maybe from your Axiom of Infinity — that gives a model for PA within ST?
I think you’ve confused Cantor with Frege a bit. I don’t think Cantor ever advocated the unrestricted comprehension principle; he described set formation much less formally as a mental act. Frege is famous for getting a contradiction by claiming unrestricted comprehension.
I also send my condolences.
Question: your definition of total seems to be different from the one given at Wikipedia, which basically states that all elements are comparable. That is, for all a,b, aRb or bRa. Your definition seems to be saying there is no bound above or below. Am I missing something here?
For PA, one probably uses Frege-numbers: A number n is the set of all sets having n members, i.e. level-2-zero is the set of the empty set, level-2-one is the set of all sets containing one level-0-object, and so on. Successor is defined something like Sx² = {y¹ | (∃z°) y¹ \ {z°} ∈ x²} (using superscripts for levels).
@FirstApproximation: Wikipedia’s page on binary relations has both meanings, the one Mark uses here is given as ‘left-total’/‘right-total’(surjective).
Ah. Thanks.
“the set of all sets that contain themselves” <- I have always seen this formulated as “the set of all sets that do not contain themselves”. I don't think the former causes the paradox. Also, I think "Well, if it is, then it is. If it isn’t, then it isn’t. Both yes and no!" is wrong?
The real problem is the set of all sets that do *not* contain themselves. But even the set of all sets that *do* contain themselves is a bit of a problem, because it’s a logical definition that should produce one thing, but instead, it produces something ambiguous.
I understand the ambiguity better, thanks.
Glad you’re back, Mark. I’ve been missing your posts, and, frankly, I was starting to worry. Sorry to hear about your mother — the loss of loved ones is hard.
Pingback: Godel (Reposts) | Good Math/Bad Math