
One of the things that topologists like to say is that a topological set is just a set with some structure. That structure is, basically, the nearness relation – a relation that allows us to talk about what points are near other points.
So to talk about topology, you need to be able to talk about nearness. The way that we do that in topology is through a fundamental concept called an open sphere. An open sphere defines the set of all points that are close to a particular point according to some metric. That’s not the only way of defining it; there are various other ways of explaining it, but I find the idea of using a metric to be the easiest one to understand.
Of course, there’s a catch. (There’s always a catch, isn’t there?) The catch is, we need to define just what we mean by “according to some metric”.Fundamentally, we need to understand just what we mean by distance. Remember – we’re starting with a completely pure set of points. Any structure like a plane, or a sphere, or anything like that will be defined in term of our open spheres – which, in turn, will be defined by the distance metric. So we can’t use any of that to define distance.
Defining Distance
So. Suppose we’ve got a totally arbitrary set of points, 



Let’s start by thinking about a simple number line with the set of real numbers. What’s the distance between two numbers on the number line? It’s a measure of how far over the number line you have to go to get from one point to the other. But that’s cheating: how far you have to go is really just a re-arrangement of the words; it’s defining distance in terms of distance.
But now, suppose that you’ve got your real number line, and you’ve got a ruler. Then you can measure distances over the number line. The ruler defines what distances are. It’s something in addition to the set of pointsthat allows you to define distance.
So what we really want to do is to define an abstract ruler. In pure mathematical terms, that ruler is just a function that takes two elements,
To be a metric, a distance function 
- Non-Negativity
: distance is never negative.
- Identity
-
; that is,
the distance from a point to itself is 0; and no two distinct points are separated by a 0 distance. - Symmetry
-
. It doesn’t matter which way you measure: the distance between two points is always the same.
- Triangle Inequality
-
.
A metric space is a pair ")
For example:
- The real numbers are a metric space with the ruler-metric function. You can easily verify that properties of a metric function all work with the ruler-metric. In fact, they are are all things that you can easily check with a ruler and a number-line, to see that they work. The function that you’re creating with the ruler is:
(the absolute value of
). So the ruler-metric distance from 1 to 3 is 2.
- A cartesian plane is a metric space whose distance function is the euclidean distance:
. In fact, for every
, the euclidean n-space is a metric space using the euclidean distance.
- A checkerboard is a metric space if you use the number of kings moves as the distance function.
- The Manhattan street grid is a metric space where the distance function between two intersections is the sum of the number of horizontal blocks and the number of vertical blocks between them.
With that, we can define the open spheres.
Open and Closed Sets
You can start moving from metric spaces to topological spaces by looking at open sets. Take a metric space, ")

")

Now, think of a subset 


 \in T")
Here’s where we can start to do some interesting things, that foreshadow what we’ll do with topological spaces. If you have two open spaces 

In fact, in a metric space
In addition to the simple gluing, we can also prove that every intersection of two open subsets is open. In fact, the intersection of any finite set of open subsets form an open subset. So we can assemble open spaces with all sorts of bizarre shapes by gluing together collections of open balls, and then taking intersections between the shapes we’ve built.
So now, think about a subspace 
 \cap T \neq \emptyset")

A subset 
Cool, my (non-US, non-trading) company is called “Metric Spaces”, I just picked this name because it sounded good, it’s nice to finally know a bit more about what it actually means! 🙂
Except I don’t get the sentence: “A point p in S is in the interior of T if/f there is some point r where B(p,r) in T”
Shouldn’t it be “some radius r”, or something else?
You’re right, it should be radius .
.
It means that characterizing an interior point goes through determining if there can be found an open space containing that point which is itself contained in the set.
To visualize, try drawing a shape on a sheet of paper, take an “interior” point (I mean, one that you intuitively understand to be so) and an “exterior” and a “border” point. Try drawing open balls about each of these types of points and see how these balls lie with respect to your shape. The definitions of adherence, interior, etc… will become clear in an instant.
I’m also struggling with that sentence.
“where B(p,r) is an element of T”
But B(p,r) is a set of points, not a single element of T. Should this have been
“where B(p,r) is a subset of T” ?
I’m also guessing that there’s supposed to be some non zero constraint on r.
The use of “its” was also confusing.
“T is an open subset of S if every element of T is in its interior.”
if every element of T is in S’s interior, or
if every element of T is in T’s interior?
Based on normal English interpretation, I’d pick the former. Since the previous sentence was about defining the interior of T, it hints at the latter.
All parenthesis in the axioms for a metric space can get dropped in this presentation without altering the meaning of those axioms. The commas can get dropped also. No change of order of symbols for functions or elements is needed to accomplish this either. I don’t think I’ve ever seen a presentation of the axioms for a metric space where parenthesis and commas actually come as necessary. This raises the question… do mathematicians really value elegance? Since the invention of Lukasiewicz notation and reverse Lukasiewicz notation, it seems like we have no choice but to answer “no!” It at least would appear they value symbolic excess… or perhaps *too many* of them don’t understand those notations as more concise.
I believe I can encapsulate examples 1. and 2. in a single example…
Suppose we consider x and y as sequences (vectors) x_1 … x_n and y_1 … y_n. Then,
= d x y abs ^ + abs ^ – x_1 y_1 n … abs ^ – x_n y_n n / 1 n, or for those who somehow enjoy a scab of parentheses
d(x, y)=abs{[abs(x_1-y_1)^n+…+abs(x_n-y_n)^n]^(1/n)}.
The first instance of the absolute value function for = n 2, or = n 2x (where x belongs to the positive integers) may look superfluous. However, as far as I understand it, one logically has to define an nth root, before defining its unique positive root. We also know of (and can demonstrate using simpler principles) that for any rational number = * ^ x n ^ x / 1 n x, and one can define any given / 1 n root this way. E. G. the / 1 2 root of a number x equals a number r such that = ^ r 2 x. So, as stated example 2 doesn’t work as a metric space, since although d x_1 y_1 and d x_2 y_2 are both positive, their / 1 2 root is not necessarily. E. G. for points (3, 5) and (7, 8) one could deduce -5 as their distance from the algebra *alone*. Or at least if one defines ^ x / 1 n off the rule of exponents for rational numbers = * ^ x n ^ x / 1 n x one could get a negative number here, which as far as I can tell works out as permissible. So, the first instance of the absolute value function here isn’t superfluous and implicitly such an assumption gets made in such a case.
Elegance is not identical with terseness.
and terseness is often unreadable!
Lukasiewicz notation is particularly ugly!
I find Lukasiewicz notation more beautiful than regular notation. Finding traditional notation more beautiful than more concise notation seems like it would mean that beauty were an acquired taste. Is not beauty a natural, as opposed to acquired, taste?
Just because you find something more beautiful doesn’t make it objectively true that it’s better.
You seem to be expressing the very peculiar notion that if *your* preference is considered beautiful that that means that beauty is objective and obvious; but if your preference isn’t, then that means that beauty is ill-defined.
You don’t have to see as much to read parenthesis-free notation as you do to read traditional mathematical notation. If “terseness is often undreadble” in this case, it seems that such holds *only when* you find it easier to read a string of more symbols than fewer ones. That seems very convincing to me that it’s not the text which makes the text more “unreadable” for you in such a situation, but rather your reading habits.
It’s not all that strange that more symbols makes a string more readable (to a point). In my studies on natural language processing (trying to get computers to understand human language), I’ve learned that humans naturally insert a lot of seemingly extraneous symbols into speech, but these symbols basically provide padding to make the sentences understandable even with a terrible signal-to-noise ratio. I see the use of standard notation the same way.
Have you ever looked at disemvowelled text? It is undeniably terser. I have never seen anyone claim that it is clearer or more beautiful.
Believe it or not, I think you probably correct here SepiaMage. However, I believe the “to a point” qualification crucial here. If a statement comes as simple or very simple in nature, then more symbols makes a string more easy to read. But, once the complexity of statements reaches a certain point, a string with spaces instead of parentheses becomes easier to read, to write, and to check. Reading a tome takes a lot more time and effort to read carefully than a moderately sized book. Does it not?
Vicki,
No, I haven’t, but I’m not sure that would apply. With prefix (or equivalently ‘forward’) parentheses notation there doesn’t exist any… or at least very near 0…. ambiguity in what the expression means in logic or mathematics. I don’t see how this would apply to a disemvowelled text. I have read books on mnemoics though, and there exist at least two distinct differences between a disemvowelled text and parentheses free notation.
One way of remembering numbers comes as to translate them into consonants. Then one adds vowels to the letters in such a way that one gets a tangible image. Then one link a ridiculous, absurd, or even strange image to remember the number. Later one can more easily remember the number by decoding it from the ridiculous image. The point here comes as that although the consonants get specified by numerals, there exists more than one possibility for consonant patterns. E. G. if I want to remember 40 in someone’s address, the consonants are r and c which I could remember by rice or race. This can’t happen in correct parenthesis free-notation.
In a disemvowelled text, so far as I can tell, one in principle has to start with the natural language. Then one deletes or removes all the vowels (at least mentally speaking). In parenthesis free notation, we don’t have to start this way, we can actually start with the parentheses free notation. When we learned to add numbers in school or at home, we probably all did this, as we started with say 4 and 6, and THEN added them together, or in postfix Lukasiewicz notation 4 6 +.
If one does computations in say logic or abstract algebra from a given table (say checking for associativity or commutativity of a given table) one might even argue that we think this way. Actually, I would argue and maintain this. We first look at which elements of a set we have in mind, find where the respective row and column of those elements intersect, and *then* compute how the operation acts on those elements. We don’t look at one element, look at the operation, and then look at the other element, and then finally do the computation. If you don’t believe me, please do computations like this yourself as a sort of experiment for your own thinking. So far as I can tell you *cannot* do something similar in a disemvowelled text necessarily.
If so, I haven’t a clear idea of what you mean by “mathematical elegance” and I doubt anyone does. What grounds do you have to back up the statement that “elegance is not identical with terseness.”? I conjecture that if we actually define the notion of mathematical elegance, it’ll end up no different than that of concision, or ignoring negative connotation suggested “terseness”.
Consider an argument like this one: Suppose that mathematical elegance differs from concision in proofs. Then proof A can be longer than proof B and end up as more elegant. Do we actually know of any examples where someone recognizes a proof which takes up a page (or much more than a page) and consider it more elegant than proof which takes up two lines of text? I know I don’t.
Wikipedia talks about a mathematical proof having elegance if it is surprisingly simple, yet effective and constructive. Parentheses-free notation ends up simpler in that it requires *less* memory to write and to figure out what the symbols mean. I don’t have to remember the traditional order of operations in arithmetical studies to figure out what
x + 2 3 5. I can figure it out, or re-figure it out, as I go along. If I want to write the previous expression in infix notation I have to either specify that addition gets performed first, or add parenthesis (which means I have to remember how to write another symbol), or accept it as potentially ambiguous. And many more examples like this could get produced. So, parentheses-free notation is simpler.
It ends up more effective in that the notation ends up more efficient in saving space on the page which the reader needs to puzzle over to figure out what the author tries to say. There exist fewer demands on the memory of the reader in parenthesis-free notation, since he/she can reconstruct what expressions mean from their order. This also makes it possible that fewer prerequisites come as needed, such as having a familiarity with order of operations in a previous setting, for the user to understand a text. That such ends up constructive comes as a consequence of having a more easily understood text at one’s disposal, since it more readily ends feedback and quicker checking of proofs and theorems. Unless I’ve missed something *the only difficulty here consists of learning a new notational scheme*, and that’s the only disadvantage to forward/reverse Lukasiewicz notation. Please point out if I’ve missed something here. Or please clarify your notion of mathematical elegance… if you *seriously* have another one.
If mathematical elegance and concision really differ, *what* makes them different? If you believe they really do differ, do they differ in anything more than prejudice towards traditional notation?
Another notion of elegance, at least in a proof, could be: “demonstrates the result as fundamental aspect of the givens, instead of a side-efect”. Proofs that depend on reducito ad absurdum, or examining three cases, might be shorter and simpler than proofs that propose a single, constructive line of argument, but they are seldom considered more elegant.
By the way, did I get assigned my avatar at random? Just curious.
The problem with linear Lukasiewicz notations is that they require far more working memory to parse semantically. In your example of
^ ^ x n / 1 n
what are the arguments of the first ^ call? Don’t sit and parse it and respond: tell me INSTANTLY.
In contrast, I can immediately tell what the arguments to each operation of (x^n)^(1/n) are, and parse them later if I need to.
The arguments of the first call comes as the result of two calls which appear after other computations get resolved. This ISN’T different than (x^n)^(1/n). Tell me, what are the arguments of the second ^ call here? What do x^n and 1/n refer to?
If you say that they refer to elements you have to remember the assumption of closure, or that x^n and 1/n both are elements in the universe of discourse specified or implied already. If 1/n means the rational number, then you already have to have the notion of a rational number inherent in your assumptions for the problem, AND you have to have a way of distinguishing between when “/” means division and when it indicates a symbol to signify that one has notated a rational number by two numbers 1 and n. You don’t need such an assumption with a Lukasiewicz notation, nor assume that closure holds, and you don’t need such a distinction between “/” as division and “/” as a signifier of a rational number in Lukasiewicz notations.
The assumption pointed out here with respect to the natural numbers requires more working memory to remember that in the first place, since one has to remember the notion of rational numbers. In Lukasiewicz notation one just has to remember the elements specified by the universe of discourse given (or implied) and the arity of the operation (both which come as needed in working memory in any notational system). Closure of x n ^ and 1 n / can get *checked* by computation. One need not know that 1/n may refer to a rational number, one can compute 1 n /. And one doesn’t need a distinction between “/” as division, and “/” as a signifier of a rational number.
That makes a lot of sense – parenthesised notation (and a lot of mathematical notation) takes advantage of our visual system’s habit of partitioning what it sees onto groups of objects. Done well, it assists understanding. Done badly, it misleads.
The last paragraph here isn’t necessarily correct. There does exist another way to avoid that difficulty. I stated the wrong exponent rule referenced… it should have gone: = ^ ^ x n / 1 n. The first abs value isn’t necessary in the paragraph before the last one.
I think you confuse the terminology here: open balls are what you call open spheres, but in Euclidean spaces the term sphere is used only for the boundary of the ball.
Typo in example 2. There’s a parenthesis that is subscripted that should be normal level.
I still dislike the “nearness” thinking – it might be usefull in the metric space but in gernerall it just makes no big sense.
For example – you point in the direction of P is near D if there is an open set (sphere) containing P and D – right? (Or to formulate it *better*: if there is an neighborhood around P that contains D) – but of course such a thing allways exists (because the set itself is allways open).
So you might say … ok, let’s just take the sets in a basis for the topological set but this fails even for the metric space (depends on what you would call near).
BTW: what does P is near D mean in an metric space? is (0,0) near (1,1) – what about (0,0) and (0.1,0.1)? When will (x,x) be near (0,0)?
That’s because you want to look at it in absolute terms. But clearly, you agree with me that it is possible to define a relation = x") is nearer to
is nearer to  than
than  based on a metric? (Take
based on a metric? (Take  with
with  a set for which a metric
a set for which a metric  is defined.
is defined.
The relation would consist of all triplets in") such that
such that  < d(x,z)") .
.
That should have been all triplets in S^3") .
.
“Near” is always a relative term, whether you’re talking about metric spaces or topological ones.
“Near” is how you think heuristically about topology, making statements like “you can keep the image of a point near a target point by staying near its preimage.” Open sets (or open metric balls[*]) are how we make those statements precise.
[*] Incidentally, we usually say “ball” here; “sphere” is the surface of a ball.
I live in Minkowski space. My metric is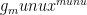 and is NOT positive definite, since I can get 0 and negative values out of that.
and is NOT positive definite, since I can get 0 and negative values out of that.
Does that mean I can’t have a topology like all the other cool spaces?
You can, but it has some weird properties compared to topologies based on “positive definite metrics”.
For instance, Minkowski space is not a Haussdorff space for its metric since two points on a light cone can never be separated.
http://en.wikipedia.org/wiki/Hausdorff_space
One could avoid that by endowing Minkowski space with the metric topology of , but that is not very natural.
, but that is not very natural.
I found this
http://www.springerlink.com/content/p3416108m3641r66/
which is about the Zeeman-order topology on Minkowski space. I don’t know anything about it, but it looks interesting.
You’re confounding two different meanings of “metric”.
Well, yeah. It fails non-negativity and identity, so Minkowski space isn’t a metric space. So does that mean you can’t do topology in 4-d spacetime?
And man, did I screw up that Latex expression. Let’s try that again:
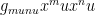
Metric is used in (at least) two different ways in mathematics, and a Lorentzian metric is a variation on Riemannian metrics, not a variation on the type of metric used in this post.
andy, seriously, stop before you get hurt.
“metric” from metric topology is NOT THE SAME THING as “metric” from differential geometry.
Sigh. There seems to be some miscommunication here. What I was actually asking was, is it possible to do topology on a Minkowski space.
Really. That’s all I wanted to know.
Acceptable answers are “Yes”, “No” or “I don’t know”.
Snide, patronizing dismissals like “stop before you get hurt” are not helpful. If that’s all you have to say, please let someone else reply.
Snide, patronizing dismissals are entirely appropriate if you respond to an initial correction by restating your original (incorrect) position. If you’re not going to read and internalize the fact that “metric” in the post doesn’t mean what you think it means, there’s nothing to be done.
And yes, it’s entirely possible to “do topology” on a Minkowski space because when you forget the indefinite inner product you’re left with a vector space. If it’s finite-dimensional over the (topological) field of real numbers, then there’s an obvious product topology (which is, incidentally, derived from a metric in the sense of the original post). If it’s infinite-dimensional, it may also have a topology. For instance, it might be the Banach space of functions on some measure space.
Banach space of functions on some measure space.
In general, I’d say they are the same. The metric from differential geometry induces a topology on your manifold (set). Whether this is the topology you want to work with is the question. In the case of Minkowski space clearly not, but you can still define a topology on it (for example the R^4 topology, but thats certainly not the only option.)
What the article is missing, in my opinion, is that the whole point of topology is to lose the whole concept of a metric. There are examples of topological spaces for which you can prove no metric can exist. (For example, the space of functions from R -> R, with the topology defined by pointwise convergence.)
If that’s true, Robert, then how come most spaces that algebraic topologists deal with are metrizable?
Algebraic topology is not my strong point, but in the bit I’ve seen of it (not much… I mainly use a bit of topology from the functional analytic side), I don’t think the metric is what people are interested in.
When you’re identifying spaces by homeomorphisms, the distances on those spaces are not being identified. In the teacup and donut example, the ear on the teacup is generally much smaller than the hole in the donut, but really you don’t care what size it is.
Of course, there are numerous theorems proving that broad classes of topological spaces are metrizable.
“So does that mean you can’t do topology in 4-d spacetime?”
Ask a physicist how they would define continuity of functions on spacetime, and I suspect you’ll find that most are implicitly using an R^4 topology on Minkowski space, and not the (useless) topology defined by the Lorentzian metric.
Ok, there is a lot of sloppy, sloppy math here. I won’t go so far as to call it bad, because it certainly isn’t malign, but you use ‘element of’ when you mean ‘contained in’. You use T to mean two different things. Etc.
Please clean this up before you proceed, or it’s not really worth reading.
I think you missed an important point at the end- an arbitary (possibly infinite, possibly uncountable) unions of open sets is still open, while only finite intersections of open sets are still open.
Also, I’d avoid using the term “open space” for open set. Seems to me that that will lead to confusion for example if you want to introduce subspace topology.
Would removing or negating the Triangle Inequality lead to anything interesting?
Metric spaces with an inverted triangle inequality collapse to a single point.
“I think you confuse the terminology here: open balls are what you call open spheres, but in Euclidean spaces the term sphere is used only for the boundary of the ball.”
QFT.
In fact, I’m pretty sure that any countable union of spheres in X will have EMPTY interior (using one version of Baire’s Category Theorem), and so cannot be equal to the whole set X.
“Would removing or negating the Triangle Inequality lead to anything interesting?”
I can’t think of a good example off the top of my head, but it would drastically change the nature of things (whereas relaxing the identity condition so that two points can be separated by zero distance does not change that much).
Many elementary proofs for metric spaces require establishing an inequality to show some kind of limiting behaviour, for example, which would cock up royally.
It seems the elegance debate reduces to “How far can we compress a proof before we can no longer satisfactorily decompress (understand) it?” Satisfactorily possibly meaning either “at all” or “without an inordinate amount of manipulation”
Nice.
“Now, think of a subset T subset S. A point p elem S is in the interior of T iff there is some point r where B(p,r) elem T.”
B’s second argument is a radius, not a point, correct? And if T is a subset of S, and B returns a set of elements from T, than I’m pretty sure you don’t mean that a ball of elements from T should be an element of T. Did you mean B(p,r) subset T?
I’ve been wrestling since the late 1960s with whether or not the Ideocosm (the space of all possible ideas) is a metric space.
What IS the distance between two ideas?
OK,
I’m very late to this game, but…
Am I misunderstanding “adherent”?
A point in a space S is adherent to a subspace T in that space S if …
the biggest ball around the point does not intersect that subspace?
In terms easier for me, if our space were the City of New York (NYC) (not including bridges and tunnels or water), and our subspace is Central Park (CP), then
Grand Central is not adherent to CP, since a ball around GCT of radius 20 blocks intersects CP, but
Yankee Stadium is adherent to CP, since no ball of any radius around Yankee Stadium intersects CP.
Is that really right?
I think you’ve got something backwards, Jonathan. Try reversing the condition and see if that helps:
A point is not adherent to a subspace
is not adherent to a subspace  if
if cap T=emptyset") .
.
That is, a point is not adherent if there is some ball of some radius around that point that doesn’t contain any point of the subspace. Conversely, a point is adherent if every ball around that point contains at least one point of the subspace.
Thanks. I read a double negative as a single. Not equal to the empty set.
Got it now.